From 90% to 100%: This is the Moment AI Agents Start Replacing Financial Data Stores
The first test for any financial AI system is straightforward: can it retrieve the exact number from source disclosures, with the correct period and unit? Daloopa’s published FinRetrieval results placed the public frontier around ~90% retrieval accuracy; on our covered UK/US/EU subset, we reached 100% retrieval accuracy. As a result, the debate and evaluation framework should now shift from raw accuracy to how useful agents are in real workflows.

Primer
Featured

Daloopa’s FinRetrieval publication was a meaningful step for financial AI. It gave the market a shared test set, transparent scoring, and a common reference point for comparing systems. That is exactly what this category needed. Instead of broad claims, teams could evaluate retrieval performance on the same questions with the same scoring logic.
It also established a practical baseline. Public results showed strong systems generally landing a little above 90%, not 100%. In finance, that is impressive progress, but it still implies operational review burden: analysts cannot fully trust outputs without defensive checking.
We ran our own benchmark evaluation with that baseline in mind.
What We Ran
FinRetrieval contains 500 questions. Our current run focused on questions where the companies were UK/US/EU based as their primary documents are already ingested and processed in our environment. That produced a covered set of 289 questions.
This scope is important to state clearly. Our current limitation on full 500 comparability is coverage completeness for the remaining companies, not a different scoring standard. We are continuing ingestion and processing for the remaining names and will publish full-set comparability as coverage completes.
Main Result
On that covered UK/US/EU set, our adjudicated result is 289/289 (100%).
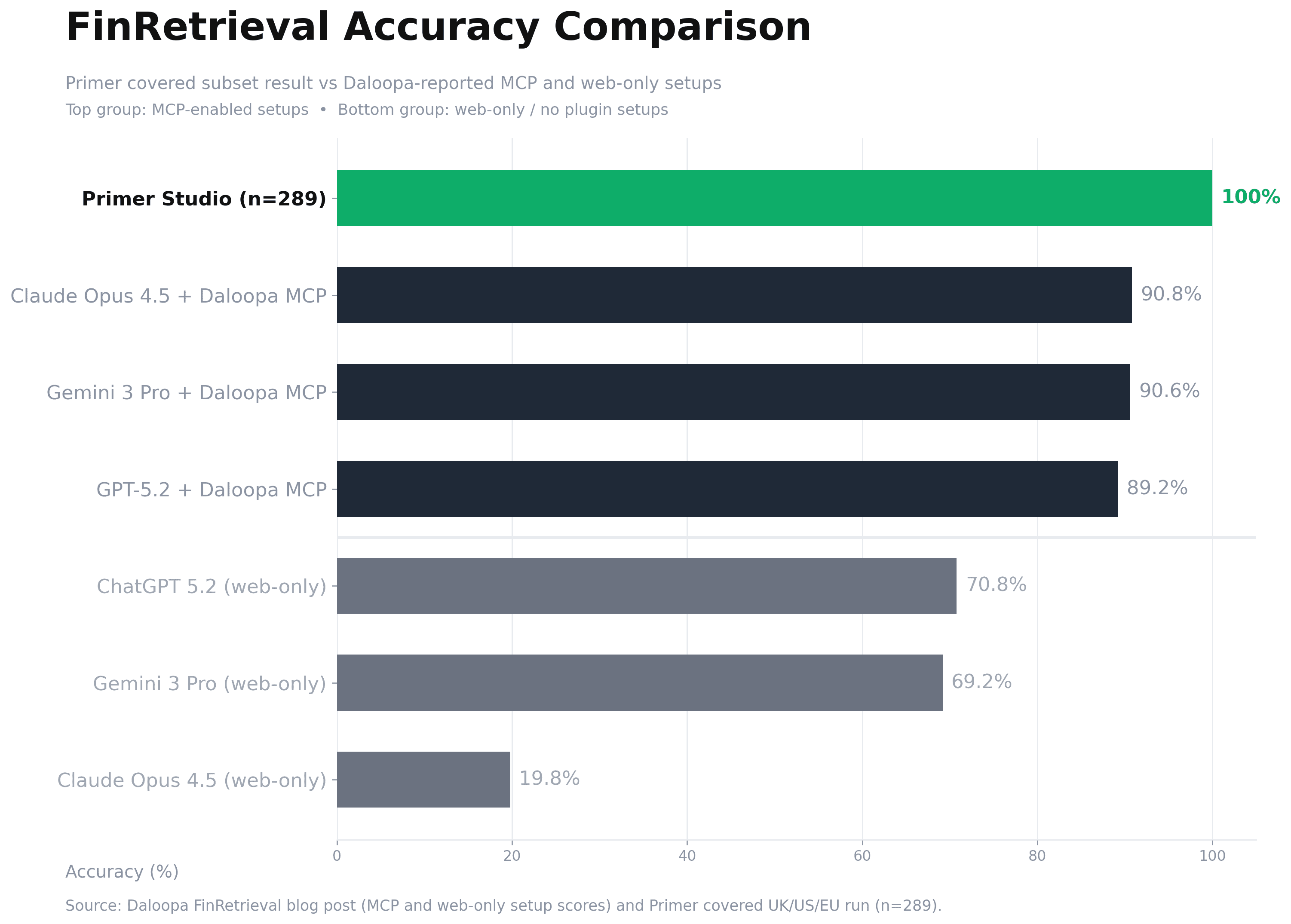
This is not yet a claim of full 500-question apples-to-apples parity, because coverage for the remaining companies is still being completed. It is a claim about the portion we can evaluate rigorously today.
Where Benchmark Labels Were Wrong in Our Review
Open evaluation only works if edge cases are reviewable. During adjudication, we found a small number of cases where primary filing evidence supported our agent answer more strongly than the benchmark label.
That should not be read as a criticism of benchmarking. It is the opposite. This is how open benchmarks improve: multiple teams run the same tests, inspect disagreements against source filings, and tighten the labels.
Three representative examples from our review:
Planet Labs (PL)
The question period appears misaligned with Planet’s fiscal calendar conventions (January 31 year-end), and the benchmark value appears inconsistent with filing evidence. In our review notes, SEC filing evidence supports -$36m guidance, not -$39m.
Ferguson (FERG:LN)
The benchmark framing expects GBP, while the filing reports the relevant discrete tax adjustment in USD after redomiciliation. The agent output aligned with filing unit context.
Winnebago (WGO)
The benchmark interpretation appears narrower than the filing presentation. The filing-level composition supports combined RV dealer inventory (Towable + Motorhome), totaling 20,812 units, which matches the agent answer.
Beyond Accuracy: The Usefulness Question
A move from low-90s to 100% on a covered benchmark slice is important, but it is not the end state. It changes the question.
At ~90%, users still work defensively: frequent checks, exception handling, and manual verification overhead. At this reliability level on covered tasks, the discussion shifts to usefulness: can the system consistently remove friction from real analyst workflows under time pressure?
That is the more commercial, more practical, and ultimately more important benchmark for this category now.


